Informatii generale
- Categorie: Utilitar
- Judetul: București
Descriere
OCR230 este o aplicație desktop creată pentru a automatiza procesarea formularelor 230, utilizate pentru redirecționarea a 3.5% din impozitul pe venit către ONG-uri. Concepută cu accent pe eficiență, siguranță și accesibilitate, aplicația folosește recunoaștere optică a caracterelor (OCR) pentru a extrage automat datele din fișiere PDF sau imagini scanate, eliminând complet munca manuală repetitivă și reducând semnificativ riscul de erori.
Motorul OCR care stă la baza aplicației este EffOCR, un model avansat, bazat pe rețele neuronale optimizate, capabil să recunoască textul cu acuratețe ridicată chiar și în cazuri dificile, formulare completate de mână, scris neclar sau scanări cu rezoluție scăzută. Astfel, aplicația poate identifica și extrage automat informații esențiale precum nume, CNP sau adresă, fără intervenție umană.
OCR230 rulează complet local, fără a necesita conexiune la internet, ceea ce oferă un grad ridicat de confidențialitate pentru datele personale procesate. Interfața grafică este intuitivă, gândită pentru utilizatori fără cunoștințe tehnice, iar procesarea este rapidă, chiar și pentru volume mari de fișiere.
Rezultatele pot fi exportate în mai multe formate utile, precum CSV, TXT sau PDF, iar fișierele sunt organizate automat pe localități și unități fiscale, pregătite pentru a fi trimise sau arhivate. OCR230 este o soluție completă, practică și fiabilă, dedicată ONG-urilor, voluntarilor și organizațiilor care gestionează anual sute sau mii de formulare 230.
Tehnologii
OCR230 este o aplicație desktop dezvoltată în Python, rulând local și complet offline, cu focus pe prelucrarea eficientă a formularelor 230.
Componenta principală de recunoaștere a textului este bazată pe EffOCR, un model de ultimă generație dezvoltat la Harvard, specializat în extragerea precisă a textului chiar și din imagini cu structură complexă sau calitate slabă.
Conversia PDF-urilor în imagini rasterizate este realizată cu ajutorul pdf2image, iar procesarea imaginilor se face prin Pillow și NumPy, care permit decupare, optimizare și transformări personalizate.
Interfața grafică este implementată în Tkinter, biblioteca standard din Python pentru GUI, folosind componente canvas și controale personalizate.
Pentru rularea în paralel a proceselor OCR și îmbunătățirea performanței la procesarea loturilor mari de fișiere, aplicația folosește modulul nativ threading.
Exportul datelor extrase se face în formate multiple: CSV, Excel (XLSX) și PDF, cu ajutorul librăriilor integrate pentru fiecare format.
Fiind o aplicație standalone, nu necesită instalare de servere, baze de date sau conexiune la internet, ceea ce sporește securitatea și confidențialitatea datelor procesate.
Cerinte sistem
Sistem de operare: Windows 10 sau 11 (64-bit)
Procesor: Intel i3 / AMD echivalent (minim), i5+ recomandat (recomandare - 2+ threads)
RAM: Minim 4 GB (8 GB recomandat pentru loturi mari de formulare)
Spațiu pe disc: ~900 MB (instalare + OCR models)
Realizatori
Rares Mihai Anghel
- Scoala: Colegiul National de Informatica Tudor Vianu
- Clasa: 10
- Judet: București
- Oras: Bucuresti
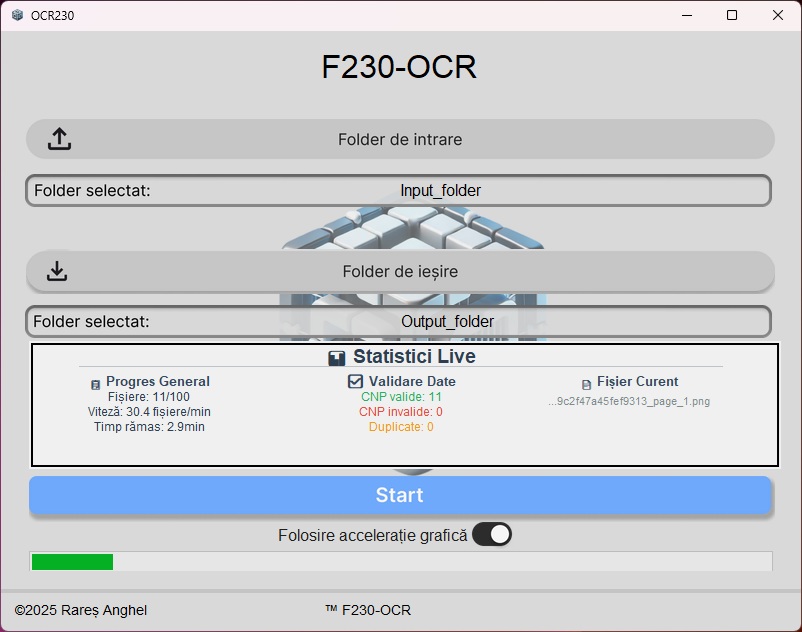
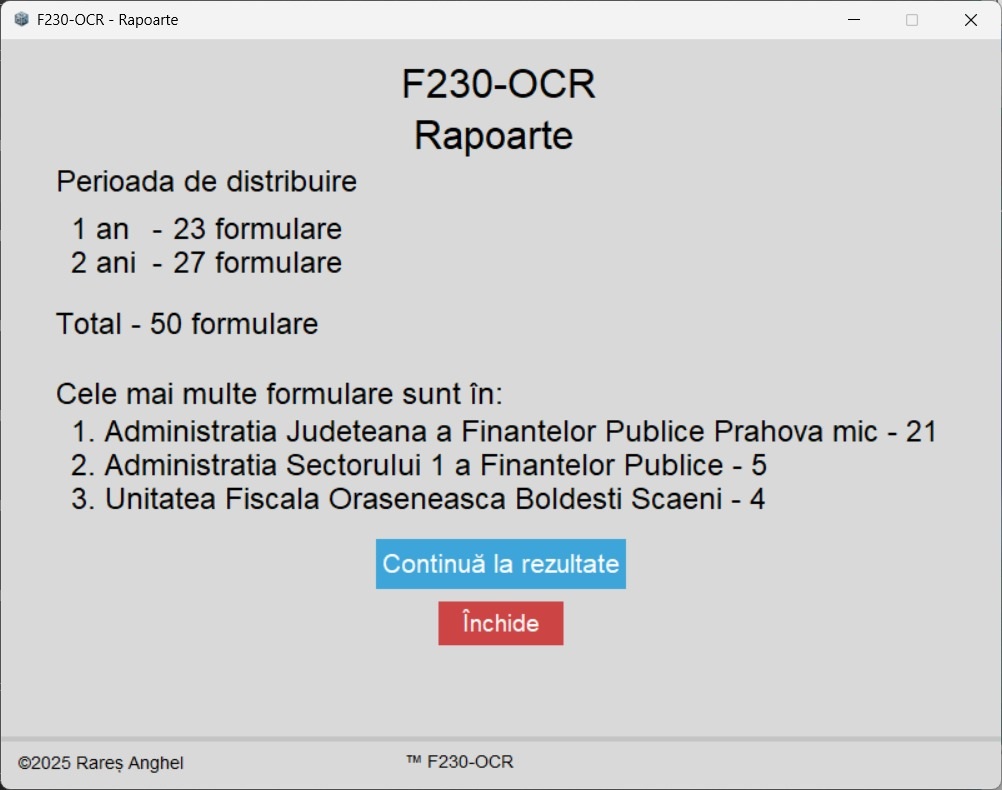
Screenshots